浙江大学廖备水教授“论新一代人工智能与逻辑学的交叉研究”线上讲座顺利举行
点击次数: 更新时间:2023-10-23
本网讯(通讯员 景海龙) 10月18日晚上,浙江大学威斯尼斯人wns579廖备水教授应邀做了题为“论新一代人工智能与逻辑学的交叉研究”的讲座,本次讲座是“武汉大学科学技术哲学论坛”系列线上讲座第七讲。讲座由威斯尼斯人wns579陈波教授主持,清华大学哲学系刘奋荣教授评议。

陈波教授主持
廖备水首先回顾了命题和推理两个逻辑学概念,从中引出演绎、归纳和溯因三种与人工智能研究关系紧密的基本推理模式。演绎推理是从一般到特殊,当给定前提和推理规则,从一组前提出发证明某个命题的成立。它是计算机和人工智能的基础,由此发展出了图灵机、专家系统和知识图谱。归纳推理是从一系列具体的证据出发概括出一般原理,前提为结论提供一定程度的支持,因此结论是或然的,由此发展出了深度神经网络。溯因推理是从结果出发,推测出事件发生的原因和过程,其结论也是或然的。它能够从已有知识和观察信息出发构建最佳解释。

廖备水教授做线上讲座“论新一代人工智能与逻辑学的交叉研究”
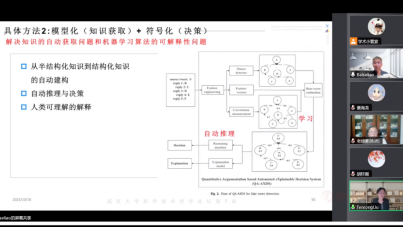
廖备水随后介绍了当前人工智能的主要研究路径及所面临的问题。当前人工智能研究主要分为符号化和模型化两种研究范式,其中符号化是通过对知识的表示与推理来实现人工智能。模型化则是通过统计方法对一些模型进行学习来实现人工智能,这种统计方法一般是深度神经网络。符号化方法首先需要建立一个知识库,知识库内是运用形式化的逻辑方法来表示的一些知识,然后将知识库内的知识作为前提,通过控制模型实现一个逻辑推理机来进行处理,并得到一个结果。这种方法被称为显式的知识表达,能够具有人类水平,且可解释性好、通用性强。但是面临着知识的表示、获取和处理代价高,知识不完备性、不确定性和不一致性的问题。模型化方法通过人工神经网络对非结构化的数据进行处理,抽取出其中的一些模式,然后得到统计模型,再根据这个统计模型做出预测,获得结果。这种方法被称为隐式的知识表达,为当前所广泛应用。但是由大数据驱动,端到端,因此面临着可解释性问题、伦理对齐问题和认知推理问题。
廖备水接着指出,符号化和模型化的方法有很强的互补性,这在现有的一些研究中已经得到证明。例如,结合模型化(知识获取)+符号化(决策),可以采用归纳逻辑编程的方法从案例中学习一般规则。对于新案例,通过基于规则的推理做出决策,从而构建人类可理解的解释。又如,结合模型化(知识获取)+符号化(知识引导),可以实现机器学习数据标注的自动化,避免传统机器学习中需要花费大量工作对数据进行标注的问题。
廖备水还在法律推理研究的启示下,提出了一种基于形式论辩,结合符号化和模型化的研究路径。法律中有很多法律规范和法律偏好可以从法律文本中获得,然后将这种法律上对知识的挖掘方法进行形式化表达。也就是说,在法律文本中应用一些机器学习的方法挖掘一些机器可读的表征,再用推理机对可获得的知识进行推理,并用人类可理解的方式进行表达。应用到人工智能上的具体方法:通过提出论证、比较论证、评估论证的方式来构建人类的推理模型。其中局部论证是可错的,然后评估其中哪些对于全局论证是可接受的。这种推理是非单调的,从而可以在获得新知识时,收回已有论证及其结论。最后将它形式化,通过局部论辩之间的相互攻击、给定评价标准、检查获得新信息后整体论辩的一致性、增加局部论证的概率表达,实现对知识不完备性、不一致性和不确定性问题的处理。
廖备水最后做了总结:(1)演绎推理、归纳推理和溯因推理这三种人类基本推理模式发挥不同作用,且经常相辅相成,共同存在于各种任务中。(2)基于知识的符号化方法是实现通用智能和提供机器学习算法可解释性的重要途径。(3)处理知识的不完备性、不一致性和不确定性问题是符号化方法的核心问题。(4)模型化方法和符号化方法的有机结合是大数据驱动人工智能研究的发展趋势。(5)形式论辩可以提供不一致情境下知识表示与推理的通用机制,与偏好、权重、概率等决策因素的灵活结合机制,局部化和模块化的语义高效计算机制,以及基于论证和对话的可解释机制。
刘奋荣教授做评议
在评议环节,刘奋荣对廖备水的报告表示感谢,并对报告内容进行了总结,然后提出了四个问题:(1)在解决机器学习算法的可解释性问题时,相关性应该如何去理解;(2)解决知识的自动获取问题中,从案例学习到的一般性伦理规则是如何学习到的;(3)目前国内外学术界在论证、偏好与统计系统相结合的研究上做了哪些工作;(4)在人机交互中高阶推理应该怎么进行,如何让机器知道我知道什么,以及我如何知道机器知道什么。
廖备水回应道:(1)相关性中每个节点都是互联网上收集到的数据,是一个人说的一句话或者一段话,现有人工智能可以对这些话的文本之间的相似关系进行定性判断,并用“正”“负”来表示,然后用近似的方法来定量它们之间的相似度。这在一定程度上反映了句子之间的支持程度。但是对于一些只是简单重复却没有支持关系但高相似度的句子与相似度低但却是强有力证据的句子应该怎么处理,目前基于统计学的研究还没有很好的方法来应对。(2)这些学习到的规则以一种命题的蕴含式被表达出来,这种蕴含关系取决于不同行为带来的实际伦理后果差别,并被以向量的方式进行形式化表达。对于这些实际伦理后果的判断标准,是由一些伦理学家们给出或者以众包的方式来统计,然后根据收集的结果对数据进行标注。(3)推荐系统事实上就是一种决策,目前学术界已经在这方面做了一些工作,其中主要有法国学者莱拉,不久前她在逻辑论辩会议上对这方面的工作做了特邀报告。(4)目前主要的相关研究是根据一个主体构建一个模型,然后基于对此的相关论证构建论证图,形成论证框架,建模成论证间的一种关系。并且,可以通过众包的方式统计大部分人对这些论证所持有的态度,形成概率表达,并选择概率更大的论证来更正论证图。但这种方法目前在更新以后的概率变化方面存在一些问题,因此它反映的只是一种一般性判断,而不是某个人所具有的特异性判断。
最后,陈波就相关逻辑学问题提出了一些观点。一般认为,演绎是从一般到特殊的推理,归纳是从特殊到一般的推理。但是这种说明方式是有问题的。例如,命题逻辑、谓词逻辑和模态逻辑中的那些演绎推理很难说成是从一般到个别的推理。同时,关于演绎和归纳的其它一些定义也存在问题。所以,究竟应该如何定义演绎和归纳,这是一个值得研究的问题。他还谈到,他不赞成“自主的中国逻辑学知识体系”的提法,因为逻辑知识是普适的,但可以做有中国特色的逻辑学研究,即聚焦一些特殊领域,使用一些特殊方法,得出一些特定的理论构造,从而扩大中国逻辑学研究在国际上的影响力。
在热烈的互动交流中,讲座圆满结束。来自国内外的800余名听众参与本次线上讲座。
(编辑:邓莉萍 审稿:严璨)